A runbook is a collection of procedures and instructions for IT operations teams to follow when performing tasks such as incident response and problem resolution as well as when following routine operational procedures. Runbooks are typically categorized by the level of automation they involve:
- Procedural/manual runbooks rely on the traditional way of documenting processes and procedures and require considerable human intervention.
- Executable/semi-automatic runbooks require minimal human intervention and can be executed using some degree of automation.
- Fully automated runbooks can be executed without human intervention.
With runbooks, you can formalize complex, iterative operational tasks as self-service workflows. Although a number of organizations leverage runbooks to document workflows as standard operating procedures (SOPs), it is worth noting the benefits of automation by implementing the steps of a runbook as executable code.
In this article, we explore core functionalities and use cases of runbooks in infrastructure management. We also explore a real-world example of how organizations can automate runbooks to improve their IT operations and the best practices to ensure the reliability and stability of a runbook automation process.
Runbooks: Key concepts
The purpose of runbook automation
As organizations continue to see the benefits of automation in IT operations, there has been increasing adoption of runbook automation to automate the execution of common tasks and procedures. Automating repetitive ITSM and infrastructure management workflows through runbooks help teams focus on more strategic tasks while ensuring that best practices are followed consistently, tasks are performed on schedule, and incidents are resolved quickly, ultimately leading to improved quality of service.
Runbook automation also helps organizations improve compliance and security by automating the execution of security protocols and ensuring that all IT operations are carried out in accordance with best practices.
Runbook functionality
Runbooks help reduce the risk of errors or disruptions caused by incorrect or unauthorized actions, and can improve the efficiency of incident response and maintenance processes. Outlining procedures and processes helps ensure that tasks are performed consistently and efficiently, while providing detailed instructions and guidelines helps ensure that tasks are performed correctly.
Runbook functionalities include:
- Automated resource provisioning / configuration management
- Helping support multiple workflow strategies
- Seamless execution across distributed environments
- Seamless integration with multiple resource models and execution systems
- Use of scripting languages to run directly from the runbook
- On-demand and scheduled job execution
- Generating reports and audit trails for runbook edit history
- Administering robust access controls
Note that as organizations look to manage different services and systems, the underlying effort to implement and maintain several runbooks simultaneously becomes a persistent challenge.
Runbook use cases
Hardening an OS instance using a standard security procedure
Runbooks are popularly used to outline the steps and procedures to secure an operating system instance from potential threats and vulnerabilities. The steps include tasks such as the following:
- Installing and updating security software to protect the OS instance from threats and vulnerabilities
- Configuring access controls and security policies
- Disabling unnecessary services and protocols to reduce the attack surface and minimize vulnerabilities
- Enabling security features such as data encryption, network segmentation, and other measures to protect the OS instance from threats
Responding to an incident using a standard procedure
Using a runbook to respond to an incident can be an effective way to minimize the impact on a service or system and mitigate the incident within SLA timelines. By outlining the procedures and processes for managing and maintaining a service or system, you can use a runbook as a reference while working on critical incidents.
To use a runbook to respond to an incident, you should first identify the incident and gather any relevant information through log files or other core vitals to help understand the cause and impact of the incident. Next, assess the severity and impact of the incident and activate the appropriate response team, if necessary. Follow the relevant runbook procedures to resolve the incident, and communicate and document the incident as needed.
A runbook containing standard procedures for incident response also helps with the following:
- Ensuring that incident response procedures are followed consistently
- Providing a clear and concise set of instructions for incident resolution
- Reducing the risk of errors or inconsistencies in response procedures
- Facilitating the collaboration and coordination of cross-functional teams during incident response
Employee onboarding and offboarding
A runbook can be used to document and standardize the processes for welcoming new employees or managing employee departures:
- An onboarding runbook includes steps such as setting up new employee accounts, provisioning access to systems and resources, and scheduling training or orientation sessions.
- An offboarding runbook, on the other hand, includes steps like revoking access to systems and resources, collecting company property, and handling outstanding issues before an employee leaves the company.
Both onboarding and offboarding runbooks standardize personnel processes across the organization. They are important parts of ensuring that the process is followed smoothly and securely to prevent any unwanted information disclosure or loss.
Runbook example
Deployment rollbacks are often time-intensive and require a deep understanding of rollback strategies to efficiently revert the deployment back to a known stable state.
In the following section, we refer to an example of a runbook that helps reliability engineers perform deployment rollbacks in a Kubernetes cluster.
Rollback plan
In our example, we consider a basic rollback plan that contains various steps to be followed by operations teams for rolling back a Kubernetes deployment. The plan outlines the tasks, roles, and deployment build to run when the rollback is invoked.
Quick note: It's essential to note that while this article provides an example of a rollback strategy, real-world rollbacks can be much more intricate and may involve non-reversible changes. For instance, changes to database structures may not be easily rolled back; eventually requiring a comprehensive strategy to prevent data loss.
Updating the deployment
For the purpose of this example, we assume that updating the deployment involves the following steps:
- Update the code repository:
- Update code changes to the cluster using the new container image.
- Verify rollout status.
Rollback
The rollback consists of two steps:
- Check the rollout history.
- Roll back the deployment to a stable version.
Verification
Finally, we verify the rollback.
- Check the rollout status.
- Check that the deployment runs as expected.
- View running pods.
Runbook automation example
In our runbook example above, some steps of the rollback runbook will always be performed manually, such as the creation, rehearsal, and updating of the rollback plan. Other parts of the runbook can be semi-automated, such as updating the code repository, where engineers can update their code manually and have the updates then be automatically shipped into production using CI/CD tools.
For this demo, we configure an Ansible script to perform a rollback automatically if there are deployment issues. The following section outlines how to create an automated runbook that triggers a rollback when pods return an ImagePullBack error.
Prerequisites and assumptions
Our example is based on the following setup:
- An Ansible controller host
- A Kubernetes cluster set up to run the deployment, apply a rollback, and utilize an Ansible module for automated runbooks
- Prometheus configured to scrape metrics from the Kubernetes cluster
- Python v3.6+ installed on both the Ansible controller host and the Kubernetes node machine
- Python modules openshift (greater than 0.6) and PyYAML (greater than 3.11) installed on both the Ansible controller host and the Kubernetes host
Configuring Prometheus to send alerts
As the first step, we configure Prometheus to monitor the status of pods within the deployment and send an alert when a pod is stuck in an image pull error.
To do so, add the following lines to the alerting: rules section of prometheus.yml, the Prometheus configuration file that is used to deploy Prometheus in a cluster.
Configuring the Ansible playbook
- On the Ansible controller host, we create the directory for the Ansible script that will execute the rollback.
- We then create the YAML file to be used for runbook task automation.
- To determine whether Ansible should trigger a rollback, it needs to listen to the Prometheus alert manager. To enable this, add the following code to the playbook.yml file, creating a webhook that triggers the playbook when an alert is generated:
- To avoid false positives, it is also important to ensure that the Ansible playbook validates the status of the pods before performing the rollback:
- The Ansible k8s module enables automated rollbacks to specific deployment versions. The following code rolls back the deployment my-deployment to version 1:
- Next, we validate playbook.yml, which would look like this:
- If the target Kubernetes cluster is not yet configured to communicate with the Ansible controller host, run the following command:
- Finally, execute the playbook on the host’s CLI by running the following command:
Quick Note:
- <user-name> specifies the username that the playbook should execute as.
- -b allows Ansible to perform tasks that require elevated privileges, such as making changes to system settings or creating/deleting deployment objects.
Executing the playbook returns an output similar to the following:

Testing the automation script
The next step is to test whether the automation script works on a deployment named my-deployment that has already been deployed and updated once. The setup involves trying to update the deployment with a nonexistent image, which results in an image pull error.
- First, check the history of the deployment rollouts.
This command returns a result similar to the following:

- Update the deployment with a nonexistent image using this command:
This command updates all containers within the deployment with a nonexistent image, sending the pods into ImagePullBackOff.

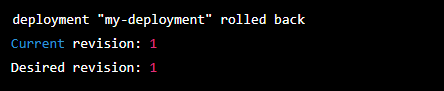
- Checking the deployment’s rollout history and the status through the following command reveals that the deployment has been rolled back to version 1.

Runbook best practices
To get the most out of runbooks, we recommend the following actions.
Start with a manual runbook
While an automated runbook can help automate repetitive tasks, a manual runbook helps document and keep track of processes that require manual judgment and decision-making. As a best practice, it is always recommended to start with a manual runbook when kickstarting your automation strategy. This allows you to document each step of the process accurately, map out dependencies between tasks, and validate the accuracy of your automation before implementing it.
Consider paid services before developing an automation script
It’s important to carefully consider the costs and benefits of developing your own automation script versus using a paid service. Custom-developed scripts may provide more flexibility and control, but they increase effort overhead. Paid services, on the other hand, offer more robust features and support, though they may come at a higher cost.
There are a few key considerations to keep in mind when deciding whether to develop an automation script for runbook automation:
- Time and resources: Developing an automation script can be time-consuming and resource-intensive.
- Expertise: Building an automation script requires a certain level of technical expertise.
- Scalability: If you expect your runbook automation needs to grow significantly over time, a paid service may be more flexible and scalable to meet your needs as they evolve.
- Support: A paid service may offer more robust support options, including dedicated technical support, which can be valuable when working with complex automation scripts.
Have a rollback plan
Rollback plans are crucial components of runbook automation to help undo changes that have been made to a system. They can be used to restore the system to a stable state if something goes wrong.
When making non-reversible changes through a Runbook, it's essential to have specific rollback or roll-forward plans as a backup. This might involve creating an individual strategy specifically for managing effects of the change or crafting more comprehensive rollback tactics that take those changes into account.
A rollback plan typically involves:
- Determining what changes you want to track
- Creating two copies of your runbook for the current version and previous version
- Creating a process for reverting back to the previous version if necessary
Although there are a few different ways to do this, the most often recommended method is to use a version control system, such as Git or SVN, to help you track and revert changes if needed. It is also important to design rollback plans before any changes are made to the system, and they should be tested regularly to ensure that they work as intended.
Understand service functions
Runbook service functions refer to specific tasks and processes that a service performs. These include tasks such as monitoring the service for performance issues, responding to alerts, implementing updates or patches, or maintaining documentation.
It is important to understand the functions of a service before automating the runbook for SREs. This includes understanding the purpose and role of the service as well as the specific tasks and processes that the service performs.
When automating a runbook, some key considerations with service functions include these:
- Correlating service dependencies to ensure that the automation process is designed optimally and does not impact dependent services
- Understanding the service architecture to assess the impact and extent of automation possible
- Analyzing service performance under different conditions to help determine which automation tasks are the most important to focus on
- Identifying the maintenance requirements of a service to ensure that the automation process follows scheduled updates and outage windows
Collect an audit trail to help optimize runbooks
Collecting an audit trail is a crucial step in optimizing runbooks for SREs. An audit trail is a record of all actions and events that have occurred within a system and is considered valuable for identifying patterns, trends, and potential issues.
To collect an audit trail, SREs can use tools such as logs, monitoring systems, and version control systems to track activities and changes made to the service. There are several ways that an audit trail can help optimize runbooks for SREs:
- Identifying patterns: By reviewing the audit trail, SREs can identify patterns and trends in the data that may be indicative of problems or areas for improvement.
- Troubleshooting: An audit trail can be helpful in troubleshooting issues with a service by identifying specific events or actions that may have contributed to an issue.
- Performance optimization: Audit trails also help SREs identify areas where the runbook may be inefficient and develop strategies to optimize those processes.
Enforce success checks using groups and permission gates
Success checks in runbook automation are essential controls that ensure that automation processes are followed correctly by validating conditions before allowing actions to be taken. Enforcing success checks helps prevent errors or disruptions caused by incorrect or unauthorized actions. The approach can further help improve the reliability and stability of automation processes and ensure that they are followed correctly.
One way to enforce success checks is through the use of groups and permissions, which involves creating groups of users who are authorized to perform certain tasks or access certain resources and then assigning permissions to groups to execute specific tasks.
Conclusion
Automating runbooks allows organizations to abstract repetitive tasks from their incident resolution workflows, improving incident resolution efficiency. Eliminating repetitive tasks also helps ensure consistency and accuracy in incident resolution, reducing the risk of errors.
Tools such as Squadcast can help store and automate runbooks, simplifying incident resolution workflows and improving overall incident resolution efficiency. This enables teams to focus on more strategic tasks rather than spending time on manual and time-consuming incident remediation.
To avoid delays and spending time looking at multiple tools to find the right checklist, Squadcast’s Runbooks feature helps you access the relevant runbook, associate it with incidents, and assign tasks to relevant users. To learn more about how Squadcast can help you improve reliability metrics by automating runbooks and simplifying incident management, book a demo here or start a free trial.













